

Explainable Artificial Intelligence (XAI) menggunakan metode-metode berbasis nearest neighbors adalah pendekatan yang memungkinkan untuk menjelaskan hasil dari model AI dengan menggunakan metode nearest neighbors. Metode ini memungkinkan untuk memahami alasan di balik prediksi yang dibuat oleh model AI.
Pendekatan ini dapat membantu dalam memahami bagaimana model AI membuat keputusan dan memberikan insight yang lebih dalam terkait dengan proses yang terjadi di dalam model AI
Dengan menggunakan metode nearest neighbors, XAI dapat memberikan penjelasan yang lebih terperinci terkait dengan alasan di balik prediksi yang dibuat oleh model AI, sehingga memungkinkan untuk memahami lebih baik bagaimana model AI tersebut bekerja.

Dengan demikian, Explainable Artificial Intelligence menggunakan metode-metode berbasis nearest neighbors adalah pendekatan yang memungkinkan untuk menjelaskan hasil dari model AI dengan menggunakan metode nearest neighbors, sehingga memberikan insight yang lebih dalam terkait dengan proses yang terjadi di dalam model AI.
Penerapan nearest neighbors dalam kecerdasan buatan yang dapat dijelaskan adalah pendekatan yang memungkinkan untuk menjelaskan hasil dari model kecerdasan buatan dengan menggunakan metode nearest neighbors. Metode ini memungkinkan untuk memahami alasan di balik prediksi yang dibuat oleh model kecerdasan buatan.
Salah satu contoh penerapannya adalah dalam pembelajaran mesin transparan dan teknik untuk sepenuhnya memahami hasil prediksi. Sebuah karya ilmiah mengusulkan kerangka kerja analitik preskriptif yang mendemonstrasikan bagaimana analitik prediktif transparan dapat dicapai dan digabungkan dengan teknik analitik preskriptif. Penelitian ini mengembangkan model prediktif untuk mengidentifikasi siswa berisiko tidak menyelesaikan program, dan mendemonstrasikan bagaimana pemodelan prediktif transparan dan bertanggung jawab dapat diperkaya dengan analitik preskriptif untuk menghasilkan umpan balik preskriptif yang dapat dibaca manusia bagi mereka yang berisiko melalui kemajuan terbaru dalam AI dengan menggunakan model bahasa besar.
Pengertian K-Nearest Neighbor (KNN)
Algoritma K-Nearest Neighbor (KNN) adalah algoritma machine learning yang bersifat non-parametric dan lazy learning. Metode yang bersifat non-parametric memiliki makna bahwa metode tersebut tidak membuat asumsi apa pun tentang distribusi data yang mendasarinya. Dengan kata lain, tidak ada jumlah parameter atau estimasi parameter yang tetap dalam model, terlepas data tersebut berukuran kecil ataupun besar.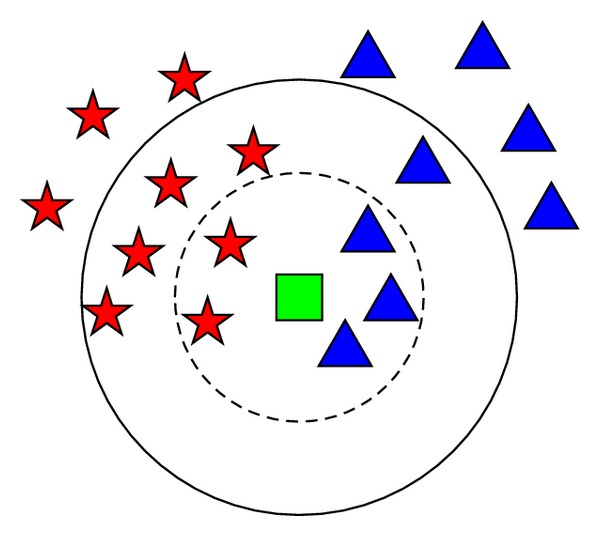
Semua data training digunakan pada tahap testing. Hal ini membuat proses training lebih cepat dan tahap testing lebih lambat dan cenderung ‘mahal’ atau membutuhkan banyak cost dari sisi waktu dan memori. Dalam kasus terburuk, KNN membutuhkan lebih banyak waktu untuk memindai semua titik data. Proses ini juga akan membutuhkan lebih banyak memori untuk menyimpan data training.
K-Nearest Neighbor termasuk salah satu algoritma paling sederhana yang digunakan dalam machine learning untuk regresi dan klasifikasi. KNN mengikuti strategi “bird of a feather” dalam menentukan di mana data baru sebaiknya ditempatkan. Algoritma KNN mengasumsikan bahwa sesuatu yang mirip akan ada dalam jarak yang berdekatan atau bertetangga. Artinya data-data yang cenderung serupa akan dekat satu sama lain.
KNN menggunakan semua data yang tersedia dan mengklasifikasikan data atau kasus baru berdasarkan ukuran kesamaan atau fungsi jarak. Data baru kemudian ditugaskan ke kelas tempat sebagian besar data tetangga berada.
Poin-poin Penting dalam Algoritma KNN
Tujuan dari algoritma k-nearest neighbor adalah untuk mengidentifikasi tetangga terdekat dari titik kueri yang diberikan, sehingga kita dapat menetapkan label kelas ke titik tersebut.Untuk mencapai tujuan tersebut, berikut ini adalah beberapa poin penting yang perlu diperhatikan:
Menentukan metrik jarak
Untuk menemukan titik serupa terdekat, kita bisa menggunakan perhitungan jarak seperti Euclidean distance, Hamming distance, Manhattan distance dan Minkowski distance.
Mendefinisikan nilai K
Mendefinisikan k dapat menjadi tindakan penyeimbang karena nilai yang berbeda dapat menyebabkan overfitting atau underfitting. Nilai k yang lebih rendah dapat memiliki varians yang tinggi, tetapi bias yang rendah. Sedangkan nilai k yang lebih besar dapat menyebabkan bias yang tinggi dan varians yang lebih rendah.
Pilihan k akan sangat bergantung pada data input karena data dengan lebih banyak outlier atau noise kemungkinan akan berkinerja lebih baik dengan nilai k yang lebih tinggi. Secara keseluruhan, disarankan untuk memilih nilai k berupa angka ganjil untuk menghindari ikatan dalam klasifikasi. Strategi cross validation juga dapat digunakan untuk membantu kita memilih k yang optimal untuk dataset yang kita miliki.
Cara Kerja Algoritma K-Nearest Neighbor
Misalkan, kita memiliki gambar makhluk hidup yang serupa dengan kucing dan anjing, tetapi kita ingin tahu apakah itu kucing atau anjing. Jadi untuk identifikasi ini, kita dapat menggunakan algoritma KNN, karena klasifikasinya berdasarkan kesamaan. Model KNN akan menemukan fitur serupa dari kumpulan data baru berdasarkan fitur yang paling mirip kemudian memasukkannya ke dalam kategori kucing atau anjing.

Langkah-1: Pilih nilai banyaknya tetangga K
Langkah-2: Hitung jarak dari jumlah tetangga K (bisa menggunakan salah satu metrik jarak, misalnya Euclidean distance)
Langkah-3: Ambil tetangga terdekat K sesuai jarak yang dihitung.
Langkah-4: Di antara tetangga k ini, hitung jumlah titik data di setiap kategori.
Langkah-5: Tetapkan titik data baru ke kategori yang jumlah tetangganya paling banyak.
Langkah-6: Model sudah siap.
Penerapan K-Nearest Neighbor
Klasifikasi adalah masalah penting dalam bidang data science dan machine learning. KNN adalah salah satu algoritma tertua namun akurat yang digunakan untuk klasifikasi pola dan model regresi.Berikut adalah beberapa area di mana algoritma k-nearest neighbor dapat digunakan:Peringkat kredit: Algoritma KNN membantu menentukan peringkat kredit individu dengan membandingkannya dengan individu yang memiliki karakteristik serupa.
- Persetujuan pinjaman: Mirip dengan peringkat kredit, algoritma k-nearest neighbor bermanfaat dalam mengidentifikasi individu yang cenderung gagal membayar pinjaman dengan membandingkan sifat mereka dengan individu serupa.
- Preprocessing data: Dataset dapat memiliki banyak nilai yang hilang. Algoritma KNN bisa digunakan untuk proses yang disebut missing data imputation yang memperkirakan nilai-nilai yang hilang.
- Pengenalan pola: Kemampuan algoritma KNN untuk mengidentifikasi pola sangat bermanfaat untuk beberapa bidang. Misalnya, membantu mendeteksi pola penggunaan kartu kredit dan menemukan pola yang tidak biasa. Deteksi pola juga berguna dalam mengidentifikasi pola dalam perilaku pembelian pelanggan.
- Prediksi harga saham: Karena algoritma KNN memiliki kemampuan untuk memprediksi nilai entitas yang tidak diketahui, ini berguna dalam memprediksi nilai saham di masa mendatang berdasarkan data historis.
- Sistem rekomendasi: Karena KNN dapat membantu menemukan pengguna dengan karakteristik serupa, KNN dapat digunakan dalam sistem rekomendasi. Misalnya, dapat digunakan dalam platform streaming video online untuk menyarankan konten yang kemungkinan besar akan ditonton oleh pengguna dengan menganalisis apa yang ditonton oleh pengguna serupa.
- Visi komputer: Algoritma KNN digunakan untuk klasifikasi gambar. Karena mampu mengelompokkan titik data yang serupa, misalnya, mengelompokkan kucing dan anjing di kelas yang berbeda, ini berguna dalam beberapa aplikasi visi komputer.
Kelebihan dan Kekurangan Algoritma KNN
Berikut adalah kelebihan dan kekurangan algoritma KNN
Kelebihan KNN
Mengingat kesederhanaan dan akurasi algoritma, KNN merupakan salah satu pengklasifikasi pertama yang sebaiknya dipelajari oleh data scientist pemula.
2. Mudah beradaptasi
Saat sampel training baru ditambahkan, algoritma KNN menyesuaikan untuk ikut memperhitungkan data baru karena semua data pelatihan disimpan ke dalam memori.
3. Memiliki sedikit hyperparameter
KNN hanya membutuhkan nilai k dan metrik jarak, yang relatif lebih sedikit jika dibandingkan dengan algoritma machine learning lainnya.
Kekurangan KNN
Untuk dataset berukuran besar, cost untuk menghitung jarak antara titik baru dan setiap titik yang ada sangat besar dan cenderung menurunkan kinerja algoritma.
2. Kurang cocok untuk dimensi tinggi
Algoritma KNN tidak bekerja dengan baik pada data berdimensi tinggi karena dengan jumlah dimensi yang besar, menjadi sulit bagi algoritma untuk menghitung jarak di setiap dimensi.
3. Perlu penskalaan fitur
Kita perlu melakukan penskalaan fitur (standarisasi dan normalisasi) sebelum menerapkan algoritma KNN ke kumpulan data apa pun. Jika kita tidak melakukannya, KNN dapat menghasilkan prediksi yang salah.
4. Sensitif terhadap noise data, missing values dan outliers
KNN sensitif terhadap noise dalam dataset. Kita perlu secara manual memasukkan nilai yang hilang dan menghapus outlier.
Dengan demikian, penerapan nearest neighbors dalam kecerdasan buatan yang dapat dijelaskan adalah salah satu pendekatan yang memungkinkan untuk menjelaskan hasil dari model kecerdasan buatan dengan menggunakan metode nearest neighbors, sehingga memberikan insight yang lebih dalam terkait dengan proses yang terjadi di dalam model kecerdasan buatan. Semoga bermanfaat.
Penutup
Sekian Penjelasan Singkat Mengenai Explainable Artificial Intelligence menggunakan metode-metode berbasis nearest neighbors. Semoga Bisa Menambah Pengetahuan Kita Semua.
